
How Companies Can Prepare Their Data for AI and Machine Learning: The Refinement of Crude Oil into Fuel
AI and Machine Learning are terms that have moved from research papers into the very core of business strategy. Just as you wouldn’t pour crude oil into a car’s gas tank expecting it to run smoothly, you can’t feed unrefined data into an AI model and expect valuable insights. In both cases, a refining process is essential. In the data universe, this refinement is encapsulated within the terms ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform), feature engineering, and ML Ops. Let’s delve into the world where raw data is the crude oil that needs to be processed into valuable fuel for AI and ML models.

1. The Business Case: Identifying Your Data Wells — The Geological Survey of Your AI Journey
The business case for any AI or machine learning initiative serves as the foundational roadmap, much like a geological survey in oil exploration. Without a clear understanding of the terrain, you’re drilling blindly and are likely to squander resources without ever striking oil. Identifying your “data wells” means figuring out which data sources are most likely to yield valuable insights that align with your strategic objectives. Here’s how to conduct this critical survey.
Understanding Your Business Objectives: The Core Samples
Before you can identify which data wells to drill into, you must have a deep understanding of your business objectives. Are you looking to improve customer retention, streamline operations, or possibly launch a new product based on predictive analytics? Each objective will direct you to different types of data.
For instance, if your goal is customer retention, your relevant data wells might be customer behavior data, customer feedback surveys, and transaction history. For operational efficiency, you could be looking at IoT sensor data, supply chain statistics, or employee productivity metrics.
Stakeholder Interviews: Consulting the Geologists
Every organization has key stakeholders who possess invaluable institutional knowledge. These are your “geologists” who can provide insights into where rich data reservoirs might be found. By consulting them, you get a clearer picture of which data sources have the most promise and which should be left untouched. Interviews with stakeholders can help you refine your data exploration strategies, saving both time and resources.
Cost-Benefit Analysis: The Feasibility Studies
Much like oil drilling, data extraction and processing come with costs. You have to weigh the potential value of the insights you might gain against the financial and labor costs of data extraction, cleaning, and analysis. This is where a robust cost-benefit analysis comes in. Determine the ROI (Return on Investment) for each potential data well to identify the most lucrative options.
Data Quality Assessment: Testing the Soil
Once potential data wells are identified, assess the quality of the data. Is it accurate, complete, and timely? Just like how soil tests can show whether a location holds promise for oil extraction, a data quality assessment can show you whether your efforts are likely to yield high-grade, usable information. Poor-quality data is like striking sludge instead of oil; it’s costly and doesn’t serve your objectives.
Legal and Ethical Considerations: The Environmental Impact
Just as oil drilling is subject to environmental regulations, data extraction is bounded by legal and ethical considerations. Where is the data coming from? Do you have the right to use it? Is it compliant with privacy regulations like GDPR or HIPAA? These questions must be part of your business case to ensure that the data wells you tap into don’t lead to legal quagmires.
Piloting: The Test Drilling
Before fully committing resources, it’s often wise to conduct a pilot test. Use a smaller dataset to test whether the insights gained can indeed contribute to your business objectives. Think of it as test drilling to check whether the identified location does indeed contain oil. This reduces risk and provides a concrete basis to scale your data efforts.
The business case is your navigational chart in the turbulent seas of data-driven projects. It helps you identify the most promising data wells and provides a structured approach to your data exploration endeavors. By understanding your objectives, consulting stakeholders, analyzing costs and benefits, assessing data quality, and considering legal ramifications, you’re more likely to strike “black gold” in the form of valuable, actionable insights that fuel your business growth.

Before any exploration and extraction can begin, companies need to identify what they hope to achieve with their AI initiatives. Whether it’s customer retention, operational efficiency, or new revenue streams, the business case serves as a geological survey to identify where the best ‘wells’ of data reside. Just like how not all oil wells promise the same yield, not all data sources are equally valuable. A well-defined business case helps identify which data sets are worth drilling into.
2. Data Collection: Drilling and Extracting — The Groundwork for Refining Your Data Asset
Once you’ve identified your data wells through a comprehensive business case, the next step in turning data into a refined, actionable asset is the data collection process. Think of this as the drilling and extraction phase in oil production. Just like an oil well can produce both crude oil and natural gas, your data sources can yield structured, semi-structured, or unstructured data, each with its own challenges and opportunities.
Data Source Identification: Locating the Drill Sites
Having completed the business case, you should already have a good understanding of which data sources are most relevant to your objectives. The focus now shifts to how to access these data repositories. Is the data within the organization or external? Is it publicly available, or are there permissions and protocols involved? These considerations determine the “drill site” logistics.
Structured vs. Unstructured Data: The Type of Drill Needed
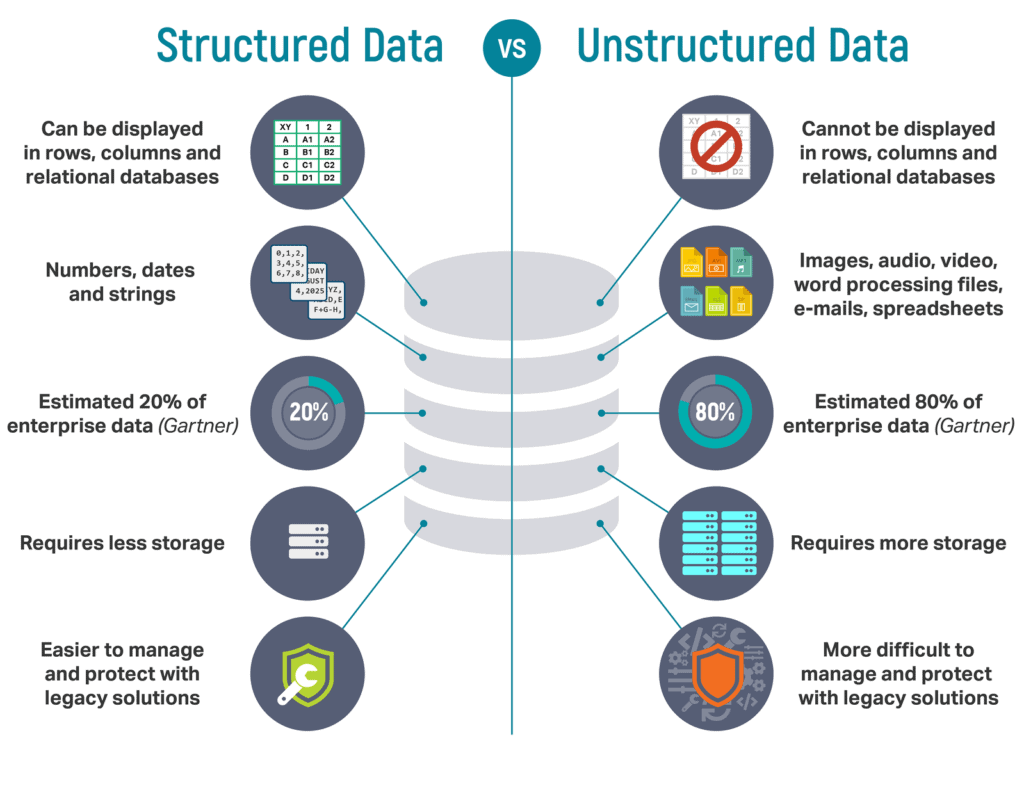
Your drilling approach changes based on what you’re looking to extract. Structured data, like relational databases, require specific extraction techniques like SQL queries. Unstructured data, which can include everything from text files to video, may require more complex extraction techniques like web scraping or natural language processing.
Time-Sensitivity: The Drilling Schedule
Some data sources are time-sensitive. Just like certain oil wells are more productive at different times, some data sources yield more valuable information during particular periods. High-frequency trading data, social media sentiment during an event, or sales data during a holiday season can be examples of such time-sensitive data sources. Thus, determining the “drilling schedule” is crucial.
Data Collection Tools: The Drilling Rigs
The tools used for data collection can range from simple data collection forms and APIs to more complex web scrapers and IoT sensors. These tools are your “drilling rigs,” and choosing the right one is essential for efficient extraction.
- For collecting customer data, surveys and CRM tools could suffice.
- For operational data, sensors and telemetry software might be more suitable.
- For public data, web scraping tools could be useful.
Automation and Scalability: The Extraction Process
As data collection scales, it becomes increasingly difficult to manage manually. Automation becomes critical at this stage. Batch processing, real-time analytics, and cloud-based data collection pipelines can help make the process more efficient and less prone to errors, just as modern oil extraction techniques have enabled more effective and safer ways to bring crude oil to the surface.
Data Provenance: The Drill Logs
Knowing where your data comes from is crucial for both compliance and quality. In oil drilling, logbooks record every detail about the drilling process, including depth, location, and materials encountered. Similarly, keeping a record of data provenance—its origin, transformations, and who has accessed it—is essential for ensuring that the data remains reliable and for meeting regulatory requirements.
Data collection is where the theoretical groundwork of the business case transitions into practical application. Much like drilling for oil, this phase involves specialized tools, techniques, and timing. Each data source requires a tailored approach for extraction, and attention to detail is paramount. Automating where possible and keeping detailed records not only ensure efficiency but also set the stage for the subsequent refining process where the real value is unlocked. Without effective drilling and extraction, even the most promising data well will remain untapped.
3. AI Data Prep & Cleaning: The Primary Refinery

Much like crude oil, raw data is often dirty, noisy, and filled with impurities. Here’s where the Extract, Transform, Load (ETL) or Extract, Load, Transform (ELT) processes come in:
- ETL: Traditionally, data was first Extracted from source systems, Transformed to fit a schema, and then Loaded into a database.
- ELT: Modern big data and cloud technologies have led to a reversal in the last two steps. Data is first Loaded into data lakes and then Transformed in-place for analytical purposes.
This stage involves data cleaning, normalization, and validation. Just as crude oil undergoes desalting, fractional distillation, and hydrocracking, raw data may undergo deduplication, normalization, and outlier detection. In some cases, this is where Vector Databases can be extremely useful in creating optimized representations of data, making them easily searchable and retrievable.
4. Feature Engineering: Secondary Refining for Specialized Fuels — Fine-Tuning Your Data for Peak Performance
Just as crude oil undergoes secondary refining to produce a range of specialized products like gasoline, diesel, and aviation fuel, raw data needs to go through the feature engineering process to generate ‘specialized fuels’ for different types of machine learning models. This stage focuses on extracting and crafting the most useful characteristics (features) from your data to power specific AI and machine learning initiatives. Let’s explore how to fine-tune your data for peak performance.
Understanding the Modeling Objective: The Fuel Requirements
Before diving into feature engineering, it’s crucial to understand what type of ‘fuel’ your machine learning model requires. The goal could be classification, clustering, regression, or something more complex. This determines what characteristics or features are most likely to be important, analogous to how different engines need different types of fuel.
Selection and Extraction: The Cracking Towers
The first step in feature engineering is feature selection and extraction. This is akin to the process of “cracking” in an oil refinery, where large molecules are broken down into smaller, more useful ones. In the data context, feature extraction means breaking down existing variables into more meaningful, informative components.
- Principal Component Analysis (PCA) for dimensionality reduction in numeric data.
- Text vectorization for turning text into a form that’s readable by machine learning models.
- Time-series decomposition in scenarios like stock price prediction or sales forecasting.
Transformation: Refining the Fractions
Once you’ve selected and extracted the raw features, they may need to be transformed into a more usable format. This is like refining different oil fractions to produce specific end products.
- Normalization and scaling ensure that the features operate on a similar scale.
- Encoding categorical variables into a numerical form.
- Imputation replaces missing or null values with estimated ones.
Feature Generation: The Blend Stocks
Sometimes, combining two or more features can produce a new feature that has higher predictive power than the individual components. This is similar to blending different stocks in oil refining to produce a specialized fuel. For example, if you’re working on a real-estate pricing model, combining the ‘number of rooms’ and ‘total area’ features could yield a new feature like ‘area per room’ that could be more informative.
Correlation and Interaction: The Quality Control
Just as the quality of refined fuel is tested to ensure it meets certain standards, the features you’ve engineered should be analyzed for their effectiveness and for how they interact with one another. Using techniques like correlation matrices or VIF (Variance Inflation Factor) can help identify whether your new features contribute to the model or if they are redundant.
Iterative Process: The Fine-Tuning
Feature engineering is often not a one-off process but an iterative one. As the model evolves or new data becomes available, features might need to be re-engineered. This is analogous to fine-tuning the refining process in an oil plant to adapt to new types of crude oil or to meet new industry standards.
Feature engineering is the secondary refining stage of your data pipeline, crucial for optimizing the performance of your machine learning models. It involves a range of techniques to select, extract, transform, and generate the most effective features. Given its pivotal role in determining the success of your AI initiatives, this process deserves careful planning, execution, and iterative fine-tuning. By investing time and resources in crafting high-quality ‘specialized fuels,’ you ensure that your AI engines run efficiently, effectively, and yield valuable insights that align with your business objectives.
5. Machine Learning and ML Ops in Production: The Combustion Engine — Powering Your Business with Refined Data
You’ve found your data wells, drilled and extracted the raw material, and refined it through feature engineering. Now, it’s time to use this specialized fuel to power your organization’s “engine”—the machine learning models that drive actionable insights and automate complex tasks. But to do so effectively, especially at scale, you need a robust ML Ops (Machine Learning Operations) strategy. Think of ML Ops as the sophisticated combustion engine that requires precise conditions and regular maintenance to keep your business vehicle moving efficiently.
Model Selection: The Engine Blueprint
The first step in the machine learning phase is selecting the type of model that aligns with your objectives. Whether it’s a decision tree for classification tasks, a neural network for deep learning, or a clustering algorithm for segmentation, the choice of the model serves as the blueprint for your engine.
Model Training: The Engine Assembly
Once you’ve selected your model, it’s time to train it using your refined data. This is analogous to assembling the components of a combustion engine. During this phase, the machine learning algorithm learns from the features you’ve engineered, adjusting its internal parameters to minimize error and improve accuracy.
Validation and Testing: The Dynamometer Test
Before putting the engine into a car, it’s tested rigorously to ensure it meets performance standards. Similarly, your model needs to be validated and tested using datasets that it hasn’t seen during the training process. Metrics like precision, recall, and F1-score can offer insights into the model’s quality.
Deployment: Firing Up the Engine
Once tested and validated, the model is ready for deployment. This is like installing the engine in a car and firing it up. In the machine learning context, this involves integrating the model into the existing tech stack so it can start making predictions or automations based on new data.
Monitoring and Maintenance: Regular Engine Checks
An engine needs ongoing maintenance to run efficiently. Similarly, machine learning models require continuous monitoring to ensure they’re performing as expected. This involves tracking metrics, logging predictions, and scanning for anomalies that could indicate model drift.
Scalability and Optimization: The Turbochargers
As your business grows, your machine learning models will need to scale. This can be analogous to adding turbochargers to an engine for enhanced performance. Cloud-based solutions, containerization with technologies like Docker, and orchestration with Kubernetes are modern ways to ensure that your machine learning models can scale with your business.
ML Ops Tools: The Mechanic’s Toolkit
Successful ML Ops relies on a range of tools that help automate, monitor, and manage machine learning models in production. These can include:
- Data Versioning Tools: To keep track of the data used for training.
- CI/CD Pipelines: For automating the testing and deployment of new models.
- Monitoring Suites: For real-time tracking of model performance.
CDO Times Bottom Line
Machine learning and ML Ops in production are where all your data refinement efforts prove their worth. Much like a combustion engine, a machine learning model needs careful selection, assembly, and ongoing maintenance for optimum performance. With the right ML Ops strategies and tools in place, you can ensure that your ‘engine’ not only starts running but keeps humming efficiently, propelling your business toward unprecedented growth and innovation.
6. Bonus Section – The Role of a Metadata Lake House: The Control Distillation Tower in Data Refinement

In the journey from raw “crude oil” data to refined, AI-ready “fuel,” the Metadata Lake House serves as the control tower. It is the oversight mechanism, the central repository where both raw and processed data coexist along with comprehensive metadata. Just as control towers manage the intricate details of drilling, pumping, storing, and shipping in oil refineries, Metadata Lake Houses manage the intricate details of data storage, access, quality, lineage, and security. Here’s how this specialized architectural feature plays a pivotal role in the data refinement process.
Central Repository: The Storage Tanks
One of the foremost functions of a Metadata Lake House is to serve as a central repository. Here, raw data coming from multiple sources—be it sales, marketing, customer interactions, or IoT sensors—is ingested and stored. The metadata provides context and meaning to the raw data, essentially ‘labeling the storage tanks’ to indicate what kind of crude is stored and what quality it is.
Data Lineage: The Pipeline Map
Metadata Lake Houses keep a historical record of data lineage—how data moves, transforms, and integrates across different points. This is akin to having a comprehensive pipeline map in an oil refinery. Knowing the lineage is crucial for quality control, regulatory compliance, and for ensuring that the data transformations actually contribute to the business objectives.
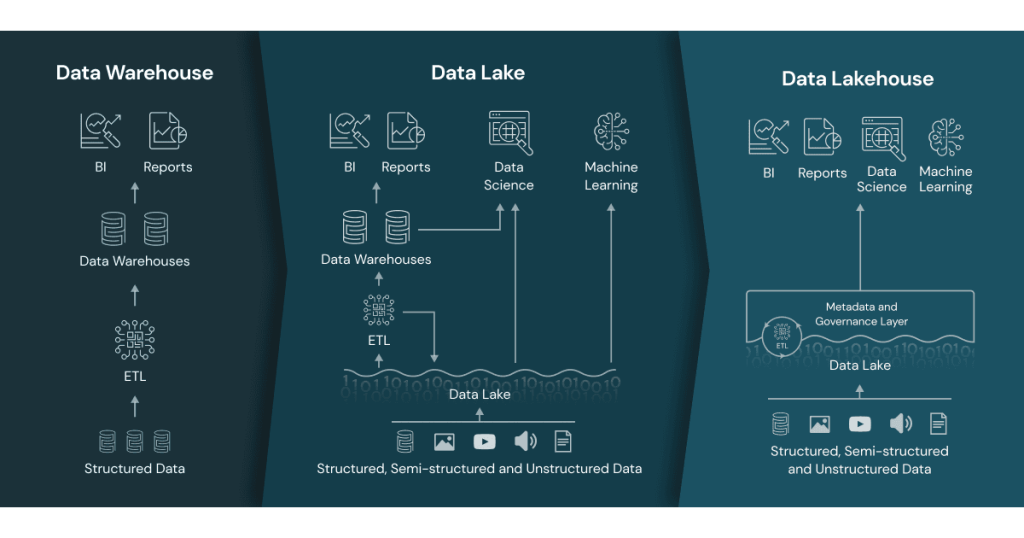
Data Governance and Quality Control: The Inspection Checkpoints
Poor data quality is the equivalent of impurities in crude oil. It can gum up the workings of any data model, rendering it ineffective or even damaging. Through robust metadata, the Lake House sets up ‘inspection checkpoints’ for data governance. It provides data quality metrics and can trigger alerts for anomalies, ensuring that only ‘high-quality crude’ moves forward in the refining process.
Data Catalog: The Index of Refined Products
As raw data gets transformed into valuable, AI-ready fuel, the Metadata Lake House maintains a data catalog—a directory of available ‘refined products’ that are ready for consumption. This index offers visibility into what kind of data is available, its source, quality, and relevant policies, thus enabling business analysts, data scientists, and decision-makers to choose the right type of ‘fuel’ for their specific use-cases.
Accelerating ETL and ELT Processes: The Refinement Units
Metadata Lake Houses can significantly speed up the Extract, Transform, Load (ETL) or Extract, Load, Transform (ELT) processes. By providing a metadata overlay on raw data, they enable automated or semi-automated transformation processes, effectively serving as efficient ‘refinement units’ that convert crude into high-quality fuel quickly and efficiently.
Security and Compliance: The Safety Protocols
Just like safety is crucial in an oil refinery, data security is vital in data architecture. Metadata Lake Houses offer robust security features, including data encryption, access control, and auditing capabilities. They serve as the ‘safety protocols’ ensuring that the data, whether crude or refined, is stored, accessed, and utilized in compliance with legal and business policies.
Architecture Patterns and Cloud Deployment Options: The Refinement Facilities and Pipelines for AI

Once your data has been cleansed and transformed into high-octane fuel, the next step is to build the engines and pipelines that make the best use of this resource. The architecture you choose is pivotal, not just for the processing of this data but also for the long-term operational sustainability of your AI and ML projects.
Architecture patterns based on use-cases, feasibility, and pros and cons.
| Architecture Pattern | Feasibility for Use-Cases | Pros | Cons |
|---|---|---|---|
| Monolithic | Small-scale applications | Simple to implement | Difficult to scale |
| Microservices | Real-time analytics, complex workflows | Scalable, Modular | Complexity in management |
| Serverless | Event-driven applications | Auto-scaling, Cost-effective | Cold starts, Resource limitations |
| Containerization | Mixed workloads | Portability, Resource efficiency | Orchestration complexity |
Architecture Patterns: The Refinement Facilities
Monolithic Architecture
Feasibility for Use-Cases:
Ideal for small-scale applications and proof-of-concept projects where simplicity and speed of deployment are essential.
Pros:
- Simplicity: Easier to develop, test, and deploy.
- Centralized Management: All processes and functionalities are bundled together, making it easier to manage.
Cons:
- Scalability: Difficult to scale horizontally.
- Flexibility: Any modification requires altering the entire application, increasing the risk of breaking functionalities.
Microservices Architecture
Feasibility for Use-Cases:
Well-suited for applications requiring real-time analytics, complex workflows, and scalable modular systems.
Pros:
- Scalability: Can easily scale individual services independently.
- Modular: Easier to update and maintain, allowing for agile development and deployment.
Cons:
- Complexity: Requires more resources for orchestration and management.
- Network Latency: Communication between multiple services can introduce latency.
Serverless Architecture
Feasibility for Use-Cases:
Best for event-driven applications, quick market tests, and applications that have variable or unpredictable workloads.
Pros:
- Auto-Scaling: Scales automatically with the number of requests.
- Cost-Effective: Pay only for the computing time you consume.
Cons:
- Cold Starts: Initial request latency due to the startup time.
- Resource Limitations: Memory and runtime constraints can be restrictive for some applications.
Containerization (Docker, Kubernetes)
Feasibility for Use-Cases:
Ideal for projects with mixed workloads, migration projects, or multi-cloud deployments.
Pros:
- Portability: Run the same code across different computing environments.
- Resource Efficiency: Better utilization of system resources compared to traditional virtualization.
Cons:
- Orchestration Complexity: Requires advanced tools and expertise for orchestration and management.
- Operational Overhead: Requires monitoring of container health and inter-service communication.
Cloud Deployment Options: The Data Pipelines
AWS (Amazon Web Services)
Pros:
- Comprehensive Service Offerings: Extensive range of services for computing, storage, and AI/ML.
- Scalability: Easily scalable to handle growing data and computational needs.
Cons:
- Pricing Complexity: Complex pricing models can lead to unexpected costs.
Azure
Pros:
- Enterprise-Friendly: Seamlessly integrates with Microsoft’s software and tools.
- Hybrid Capabilities: Strong support for hybrid cloud deployments.
Cons:
- Learning Curve: Can be complex and daunting for those not familiar with Microsoft’s ecosystem.
Google Cloud Platform (GCP)
Pros:
- Data and Analytics Strength: Strong offerings in data analytics and open-source technologies.
- Kubernetes Native: Ideal for containerized applications.
Cons:
- Smaller Ecosystem: Fewer third-party integrations compared to AWS and Azure.
IBM Cloud
Pros:
- AI and Machine Learning: Strong focus on AI and ML services.
- Multi-Cloud Support: Supports various cloud deployment models, including multi-cloud and hybrid cloud.
Cons:
- User Experience: Some users find the interface less intuitive compared to other leading cloud providers.
Choosing the right architecture and cloud deployment options is akin to selecting the right refinery setup for crude oil. Each choice has its own set of advantages and disadvantages, and the best choice often depends on the specific needs and complexities of your project. As data continues to be the “crude oil” for businesses, refining it into actionable insights through well-planned architecture and cloud deployment strategies becomes the game-changer in the competitive landscape.
Whether you’re setting up a simple refinery or a complex, multi-tiered processing plant, the key is to ensure that it’s optimized for the kind of ‘fuel’ you are producing. After all, the quality of your ‘refined product’ will ultimately determine how well your business ‘machinery’ performs.
CDO Times Bottom Line
The journey from crude data to refined insights is a complex but essential process. By aligning your business case, efficiently extracting and cleaning your data, judiciously engineering features, and managing the ML lifecycle, you prepare your enterprise to power up the AI engines effectively. Understanding and navigating this journey aren’t just an IT requirement but a core business competency in the data-driven world of today.
In a way, the quality of your refined data—just like refined oil—determines the efficiency and effectiveness of the machine it powers. As you proceed to leverage AI and ML, remember, refined data is the high-octane fuel that powers your enterprise’s AI-driven future.
Love this article? Embrace the full potential and become an esteemed full access member, experiencing the exhilaration of unlimited access to captivating articles, exclusive non-public content, empowering hands-on guides, and transformative training material. Unleash your true potential today!
Order the AI + HI = ECI book by Carsten Krause today! at cdotimes.com/book

Subscribe on LinkedIn: Digital Insider
Become a paid subscriber for unlimited access, exclusive course content, no ads: CDO TIMES
Do You Need Help?
Consider bringing on a fractional CIO, CISO, CDO or CAIO from CDO TIMES Leadership as a Business Consulting Service. The expertise of CDO TIMES becomes indispensable for organizations striving to stay ahead in the digital transformation journey. Here are some compelling reasons to engage their experts:
- Deep Expertise: CDO TIMES has a team of experts with deep expertise in the field of Cybersecurity, Digital, Data and AI and its integration into business processes. This knowledge ensures that your organization can leverage digital and AI in the most optimal and innovative ways.
- Training, developing, arranging, and conducting educational conferences and programs and providing courses of instruction.
- Strategic Insight: Not only can the CDO TIMES team help develop a Digital & AI strategy, but they can also provide insights into how this strategy fits into your overall business model and objectives. They understand that every business is unique, and so should be its Digital & AI strategy.
- Future-Proofing: With CDO TIMES, organizations can ensure they are future-proofed against rapid technological changes. Our experts stay abreast of the latest AI, Data and digital advancements and can guide your organization to adapt and evolve as the technology does.
- Risk Management: Implementing a Digital & AI strategy is not without its risks. The CDO TIMES can help identify potential pitfalls and develop mitigation strategies, helping you avoid costly mistakes and ensuring a smooth transition with fractional CISO services.
- Competitive Advantage: Finally, by hiring CDO TIMES experts, you are investing in a competitive advantage. Their expertise can help you speed up your innovation processes, bring products to market faster, and stay ahead of your competitors.
By employing the expertise of CDO TIMES, organizations can navigate the complexities of digital innovation with greater confidence and foresight, setting themselves up for success in the rapidly evolving digital economy. The future is digital, and with CDO TIMES, you’ll be well-equipped to lead in this new frontier.
Do you need help with your digital transformation initiatives? We provide fractional CAIO, CDO, CISO and CIO services, do a Preliminary ECI and Tech Navigator Assessment and we will help you drive results and deliver winning digital and AI strategies for you!
Subscribe now for free and never miss out on digital insights delivered right to your inbox!
Turn insight into action with CDO TIMES.
CDO TIMES helps executives move from AI awareness to AI execution through practical frameworks, tools, executive research, and advisory support.
Explore the Frameworks
Continue with Enterprise AI 2030, HI + AI = ECI, AI Governance, and executive playbooks.
Explore Enterprise AI 2030 →Use the Free Tools
Assess readiness, estimate AI ROI, model AI costs, and prioritize AI initiatives.
Open Executive Tools →Read the Book
Explore the HI + AI = ECI leadership model in The AI-Ready Leader.
Order The AI-Ready Leader →Go deeper with CDO TIMES Pro.
Unlock premium research, executive playbooks, templates, advanced tools, and member-only briefings.
Need executive help?
Explore advisory, workshops, fractional CIO/CDO/CISO/CAIO support, and AI operating model design.
Explore Advisory →Attend executive events
Join leadership forums, executive dinners, webinars, and strategic AI briefings.
View Events →Build AI capability
Use CDO TIMES Academy for executive learning, AI leadership development, and implementation training.
Explore Academy →




